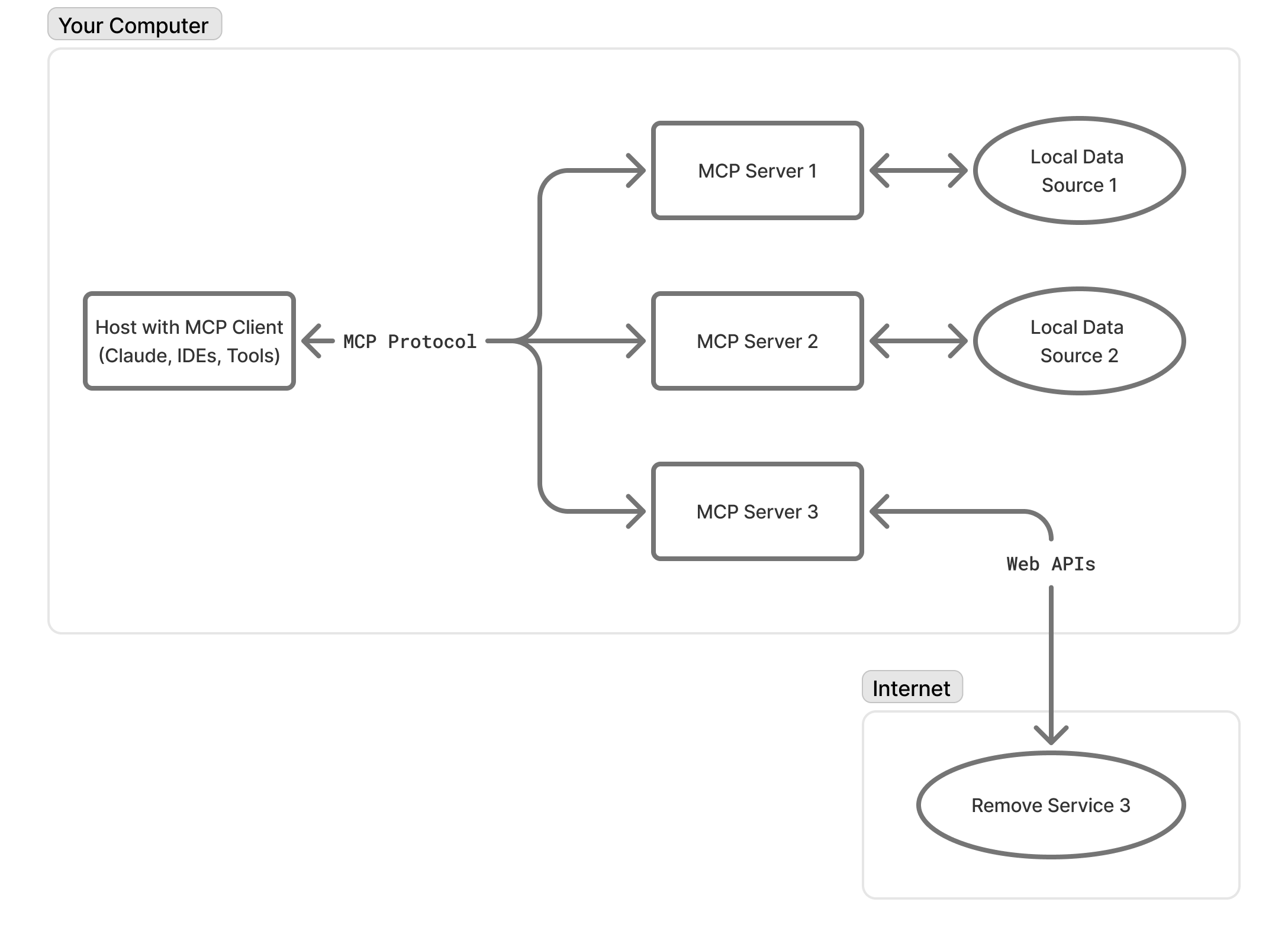
 ## Key Concepts: Host, Server, and Client
MCP is built around three main concepts:
### Host
The Host is an AI application that has implemented support for the protocol. For example, Claude Desktop was the first to support MCP. In contrast, ChatGPT does not currently support MCP, though time will tell if they eventually adopt it or develop their own standard.
### Server
The Server is what developers build to expose tools, files, or other capabilities for use by large language models (LLMs). If you’re developing custom features, you’re typically creating an MCP Server for existing applications to leverage.
### Client
The Client is the 1:1 connection with the server. Essentially, this is the component implemented by host applications (like those from Anthropic) that manages the dedicated connection to an MCP Server.
In most cases, unless you’re building your own chat client, you’re focused on developing custom MCP Servers for integration with existing hosts.
## MCP Server Overview
MCP provides SDKs for Python, TypeScript, Java, and Kotlin, making it straightforward to add custom capabilities. There are three main types of capabilities:
- Resources: Files or data that clients can read.
- Tools: Functions that can be called by LLMs.
- Prompts: Pre-written templates that help users accomplish specific tasks.
If you’re already familiar with LLM function calling, you’ll find that tool usage is quite intuitive.
Example: Adding a Weather Tool with the TypeScript SDK
Below is an example of how to add a custom weather tool using the TypeScript SDK:
```typescript
// Create an MCP server
const server = new McpServer({
name: 'Demo',
version: '1.0.0',
})
// Add a weather tool
server.tool(
'get_weather',
{ city: z.string().describe('City you want the weather for') },
async ({ city }) => {
const res = await fetch(`https://some-weather-api.com/${city}`)
const data = await res.json()
return {
content: [{ type: 'text', text: data.forecast }],
}
},
)
// Start receiving messages on stdin and sending messages on stdout
const transport = new StdioServerTransport()
await server.connect(transport)
```
For more details on resources and prompt templates, check out the Resources Documentation and the Prompts Documentation.
## How Does MCP Differ from Function Calling?
At first glance, you might wonder why MCP is needed when you can simply use function calling and prompt injection to add files or data to an LLM’s context. The key difference is that MCP is designed to integrate third-party capabilities into existing AI applications. If you’re building your own chat interface, you can handle context and function calling yourself, retaining full control.
However, if your application grows and users begin requesting additional features, supporting MCP allows third-party developers to add new functionalities to your application. For instance, imagine if Claude could seamlessly integrate your tools—for fetching sports scores or nearby bus schedules—without requiring you to build a new chat interface from scratch. That’s where an MCP Server comes in.
## Concerns and Areas for Improvement
There are a few points that could be improved:
### UI Control over Tool Calls
When you add custom tools to your MCP Server, you have no control over how tool calls are rendered in the host application’s UI. The host will display the tool calls in its own predetermined style.
### User Prompts for Tool Execution
Most applications prompt the user for permission before executing a tool. While this is a good safety measure, it would be beneficial if the MCP allowed you to specify the operation type:
- Read Operations: These could run automatically.
- Mutating Operations: These should continue to prompt the user for confirmation.
### Uncertain Future of the Standard
Since MCP is still new, it remains to be seen whether it will become the de facto standard. There’s also the possibility that other major players like OpenAI may develop their own protocols, leading to a fragmented ecosystem.
### Ease of Use and Deployment
Currently, installing MCP Servers on a host application isn’t very user-friendly for non-technical users. While this may improve in the future, it remains a barrier to adoption. Moreover, most MCP Servers are local at the moment, though development is underway to support remote MCP Servers.
### Statefulness Challenges and Compatibility Issues
The Model Context Protocol (MCP) has been critiqued for its reliance on stateful, long-lived connections between clients and servers. This design supports features like bidirectional notifications and server-initiated actions but poses challenges for serverless environments that favor short-lived, stateless interactions. Such environments often auto-scale and limit request durations, making MCP's statefulness less compatible with modern deployment practices.
Update: But this might change in near future, a [RFC](https://github.com/modelcontextprotocol/specification/discussions/102) (request for comments) was made that suggests that the HTTP+SSE transport should be replaced with “Streamable HTTP” transport. This would make it easier to host MCP servers in serverless enviroments due to its stateless nature.
### Lack of Built-in Authentication and Security Concerns
Additionally, MCP currently lacks built-in authentication and authorization mechanisms, leaving these responsibilities to individual implementations. This omission can lead to inconsistent security practices and complicate the integration process, as developers must devise custom solutions to safeguard interactions between clients and servers.
## What does this mean for SaaS-companies
If your SaaS provides valuable data or functionality that AI assistants or external tools might need, you should consider hosting an MCP server to expose controlled access. If your SaaS includes built-in AI features that require contextual data from external sources (e.g., pulling documents, CRM records, or logs), you should implement an MCP client to fetch that information.
You should build an MCP server when your product is a data source or a tool provider (e.g., project management platforms, databases, or ticketing systems) and external AI agents need structured access to your data. Conversely, use MCP client support if your SaaS product consumes external context (e.g., an AI-powered dashboard pulling insights from connected services). For AI-heavy SaaS products, both a host and client approach might be necessary—allowing bidirectional interactions where your AI features can both retrieve and serve data dynamically.
## Useful links
- [Model Context Protocol Documentation](https://modelcontextprotocol.io/introduction)
- [Awesome MCP Servers](https://github.com/punkpeye/awesome-mcp-servers)
- [Awesome MCP Clients](https://github.com/punkpeye/awesome-mcp-clients/)
---
### Synthetic Data in 2025: Revolutionizing GenAI Model Performance
URL: https://www.intentface.com/stream/synthetic-data-in-2025-revolutionizing-genai-model-performance
## Introduction
Synthetic data generation has advanced significantly, with larger language models now being leveraged for knowledge distillation to produce high-quality training examples. It enables the creation of domain-specific datasets that can be used to finetune smaller or specialised models while preserving accuracy, lowering computational costs, and reducing existing data requirements.
For instance, this approach enables efficient finetuning of GPT-4o, Llama etc. for specific use cases with just a few synthetic examples, or training specialized ModernBERT models for classification tasks within your agentic workflow \- achieving better performance on downstream tasks while requiring only a fraction of the computing resources. This is particularly valuable for high-throughput, latency-sensitive applications like LLM routing or real-time classification tasks, especially in agentic workflows where multiple models are used in sequence \- each round of model inference compounds the efficiency benefits and reduces overall latency.
---
## Key Concepts: Host, Server, and Client
MCP is built around three main concepts:
### Host
The Host is an AI application that has implemented support for the protocol. For example, Claude Desktop was the first to support MCP. In contrast, ChatGPT does not currently support MCP, though time will tell if they eventually adopt it or develop their own standard.
### Server
The Server is what developers build to expose tools, files, or other capabilities for use by large language models (LLMs). If you’re developing custom features, you’re typically creating an MCP Server for existing applications to leverage.
### Client
The Client is the 1:1 connection with the server. Essentially, this is the component implemented by host applications (like those from Anthropic) that manages the dedicated connection to an MCP Server.
In most cases, unless you’re building your own chat client, you’re focused on developing custom MCP Servers for integration with existing hosts.
## MCP Server Overview
MCP provides SDKs for Python, TypeScript, Java, and Kotlin, making it straightforward to add custom capabilities. There are three main types of capabilities:
- Resources: Files or data that clients can read.
- Tools: Functions that can be called by LLMs.
- Prompts: Pre-written templates that help users accomplish specific tasks.
If you’re already familiar with LLM function calling, you’ll find that tool usage is quite intuitive.
Example: Adding a Weather Tool with the TypeScript SDK
Below is an example of how to add a custom weather tool using the TypeScript SDK:
```typescript
// Create an MCP server
const server = new McpServer({
name: 'Demo',
version: '1.0.0',
})
// Add a weather tool
server.tool(
'get_weather',
{ city: z.string().describe('City you want the weather for') },
async ({ city }) => {
const res = await fetch(`https://some-weather-api.com/${city}`)
const data = await res.json()
return {
content: [{ type: 'text', text: data.forecast }],
}
},
)
// Start receiving messages on stdin and sending messages on stdout
const transport = new StdioServerTransport()
await server.connect(transport)
```
For more details on resources and prompt templates, check out the Resources Documentation and the Prompts Documentation.
## How Does MCP Differ from Function Calling?
At first glance, you might wonder why MCP is needed when you can simply use function calling and prompt injection to add files or data to an LLM’s context. The key difference is that MCP is designed to integrate third-party capabilities into existing AI applications. If you’re building your own chat interface, you can handle context and function calling yourself, retaining full control.
However, if your application grows and users begin requesting additional features, supporting MCP allows third-party developers to add new functionalities to your application. For instance, imagine if Claude could seamlessly integrate your tools—for fetching sports scores or nearby bus schedules—without requiring you to build a new chat interface from scratch. That’s where an MCP Server comes in.
## Concerns and Areas for Improvement
There are a few points that could be improved:
### UI Control over Tool Calls
When you add custom tools to your MCP Server, you have no control over how tool calls are rendered in the host application’s UI. The host will display the tool calls in its own predetermined style.
### User Prompts for Tool Execution
Most applications prompt the user for permission before executing a tool. While this is a good safety measure, it would be beneficial if the MCP allowed you to specify the operation type:
- Read Operations: These could run automatically.
- Mutating Operations: These should continue to prompt the user for confirmation.
### Uncertain Future of the Standard
Since MCP is still new, it remains to be seen whether it will become the de facto standard. There’s also the possibility that other major players like OpenAI may develop their own protocols, leading to a fragmented ecosystem.
### Ease of Use and Deployment
Currently, installing MCP Servers on a host application isn’t very user-friendly for non-technical users. While this may improve in the future, it remains a barrier to adoption. Moreover, most MCP Servers are local at the moment, though development is underway to support remote MCP Servers.
### Statefulness Challenges and Compatibility Issues
The Model Context Protocol (MCP) has been critiqued for its reliance on stateful, long-lived connections between clients and servers. This design supports features like bidirectional notifications and server-initiated actions but poses challenges for serverless environments that favor short-lived, stateless interactions. Such environments often auto-scale and limit request durations, making MCP's statefulness less compatible with modern deployment practices.
Update: But this might change in near future, a [RFC](https://github.com/modelcontextprotocol/specification/discussions/102) (request for comments) was made that suggests that the HTTP+SSE transport should be replaced with “Streamable HTTP” transport. This would make it easier to host MCP servers in serverless enviroments due to its stateless nature.
### Lack of Built-in Authentication and Security Concerns
Additionally, MCP currently lacks built-in authentication and authorization mechanisms, leaving these responsibilities to individual implementations. This omission can lead to inconsistent security practices and complicate the integration process, as developers must devise custom solutions to safeguard interactions between clients and servers.
## What does this mean for SaaS-companies
If your SaaS provides valuable data or functionality that AI assistants or external tools might need, you should consider hosting an MCP server to expose controlled access. If your SaaS includes built-in AI features that require contextual data from external sources (e.g., pulling documents, CRM records, or logs), you should implement an MCP client to fetch that information.
You should build an MCP server when your product is a data source or a tool provider (e.g., project management platforms, databases, or ticketing systems) and external AI agents need structured access to your data. Conversely, use MCP client support if your SaaS product consumes external context (e.g., an AI-powered dashboard pulling insights from connected services). For AI-heavy SaaS products, both a host and client approach might be necessary—allowing bidirectional interactions where your AI features can both retrieve and serve data dynamically.
## Useful links
- [Model Context Protocol Documentation](https://modelcontextprotocol.io/introduction)
- [Awesome MCP Servers](https://github.com/punkpeye/awesome-mcp-servers)
- [Awesome MCP Clients](https://github.com/punkpeye/awesome-mcp-clients/)
---
### Synthetic Data in 2025: Revolutionizing GenAI Model Performance
URL: https://www.intentface.com/stream/synthetic-data-in-2025-revolutionizing-genai-model-performance
## Introduction
Synthetic data generation has advanced significantly, with larger language models now being leveraged for knowledge distillation to produce high-quality training examples. It enables the creation of domain-specific datasets that can be used to finetune smaller or specialised models while preserving accuracy, lowering computational costs, and reducing existing data requirements.
For instance, this approach enables efficient finetuning of GPT-4o, Llama etc. for specific use cases with just a few synthetic examples, or training specialized ModernBERT models for classification tasks within your agentic workflow \- achieving better performance on downstream tasks while requiring only a fraction of the computing resources. This is particularly valuable for high-throughput, latency-sensitive applications like LLM routing or real-time classification tasks, especially in agentic workflows where multiple models are used in sequence \- each round of model inference compounds the efficiency benefits and reduces overall latency.
---